ペパレス > コラムTOP > OCRソフト「e.Typist」 58か国語の検証
近年ではインターネットの普及やグローバル化の影響で、英語を含む様々な言語を利用する人も増加傾向にあります。
この数年で翻訳ツールが増加して精度も向上していますが、それらのツールを利用する場合、大抵はテキスト情報を入力する必要があります。
そのテキスト情報を書籍や書類などの紙媒体から抽出するのがOCRソフトの役目なのですが、殆どのソフトは英語と日本語しか認識できません。
それ以外の幅広い言語に対応しているOCRソフトの1つが、株式会社エヌジェーケーから販売されている「活字OCRソフト e.Typist」です。
初代が1995年発売というロングセラーのソフトで、対応言語は58か国語です。

世界に存在する言語の数は数千種類とも言われていますが、これだけあれば主要なものはほぼ対応していると思われます。
e.TypistではOCR認識を行ったあと、PDFやWord、Excelへ転送したり、Webブラウザで開いたりすることができます。
日本語や英語以外の言語を利用されている方にとっては唯一無二の大変助かるツールになり得ます。
この度ペパレスでは58か国語全てでOCR認識を行い、
について検証しました。
検証の流れは
としています。
また、これは認識精度の検証を目的としていますので、翻訳結果に誤りがある可能性があります。
その点はご了承ください。
なお、検証は「e.Typist v.12.0」で行いました。
最新のバージョン「e.Typist v.15.0」とは異なる部分もあると考えられます。その点を踏まえたうえで、参考にしてください。
Google翻訳で対応していない言語も同様です。
ニュージーランド英語は英語のバリエーションの一つで、綴りはイギリス英語式ですが、独特のイントネーションや語彙があります。よって、一般的な英語とは区別されています。
様々な言語をOCRするとなると、日本語やラテン文字以外も文字も勿論対象となります。
しかし、e.Typistの初期設定では、欧米言語は一般的なラテン文字以外が文字化けして表示されます。
文字化けはバグと勘違いされてしまうケースも少なくないと思いますが、このソフトでは設定で対処できます。
手順は次の通りです。
「ツール」→「環境設定」→「フォント」→「表示フォント設定」→「文字セット」
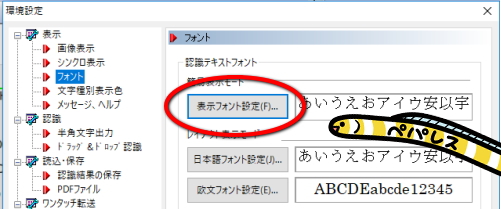
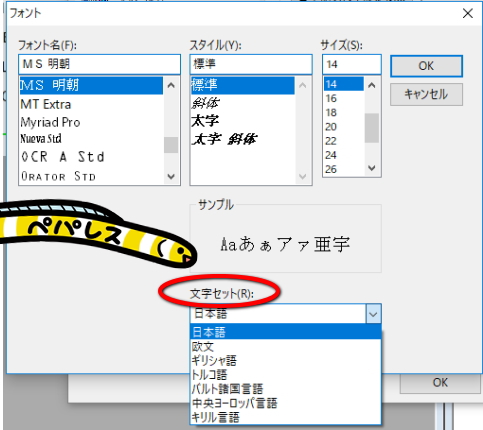
文字セットは日本語、欧文、ギリシャ語、トルコ語、バルト諸国言語、中央ヨーロッパ言語、キリル言語から選択できます。
認識結果に文字化けが生じている場合、この文字セットを適切なものにすると殆どの場合は解消されます。
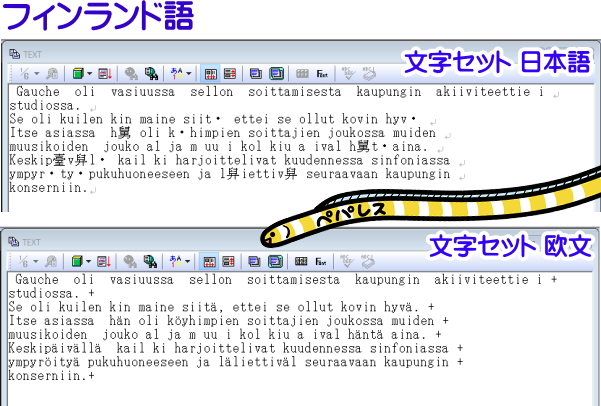
例として、フィンランド語のOCR認識結果をご覧ください。
初期設定では文字化けがありましたが、文字セットを「欧文」に設定するとこのように修正されました。
では、本題の検証結果です。
実際にOCR認識を行った結果を、言語のカテゴリー毎にまとめました。
認識精度に加え、出力形式の検証はWord、HTML、PDF(分かりやすくするため、形式は認識結果PDF)の3つとします。
基本的には同じ例文を使用していますが、Google翻訳が対応していないものは、Wikipediaなど他のWebサイトから画像をお借りしてOCR認識を行いました。
評価は○、△、×の三段階で
○…認識精度80%以上/正確に表示
△…認識精度50~79%/一部文字化け
×…認識精度50%未満/全て文字化け
としています。
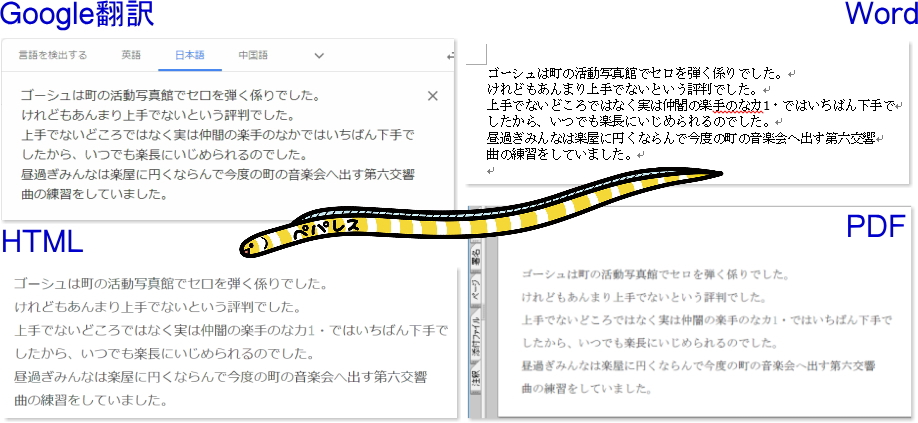
【例文】宮沢賢治『セロ弾きのゴーシュ』より引用
【日本語・英語】
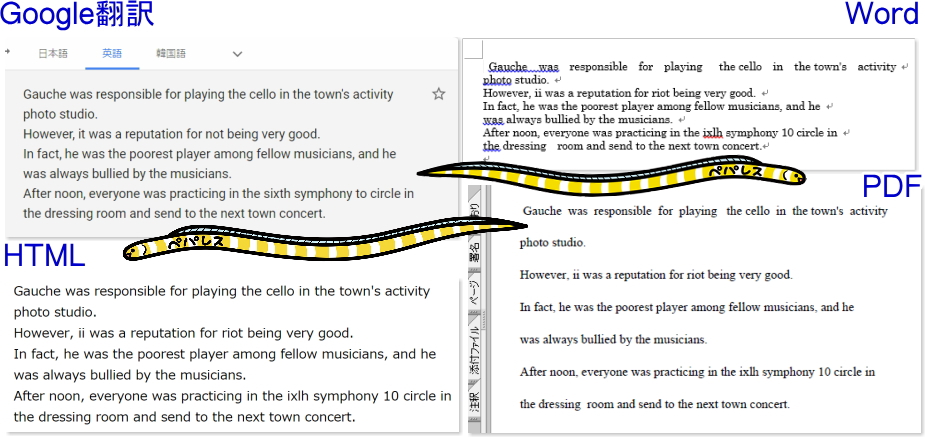
一部誤認識はありましたが、殆どは正確にOCR認識されました。
いずれもWord、HTML、PDF、それぞれに出力することもできました。
・日本語
・英語
【欧米言語】
認識精度は全て問題ないと言えるレベルでした。
ロシア語以外WordやPDFへの転送も問題ありませんでしたが、Webブラウザでは文字化けするものが多かったです。
ロシア語は出力すると、全て文字化けしてしまいました。
全ての言語でそれぞれの出力結果を掲載すると膨大な画像の量になりますので、画像はポイントを絞ってあげています。
・ドイツ語
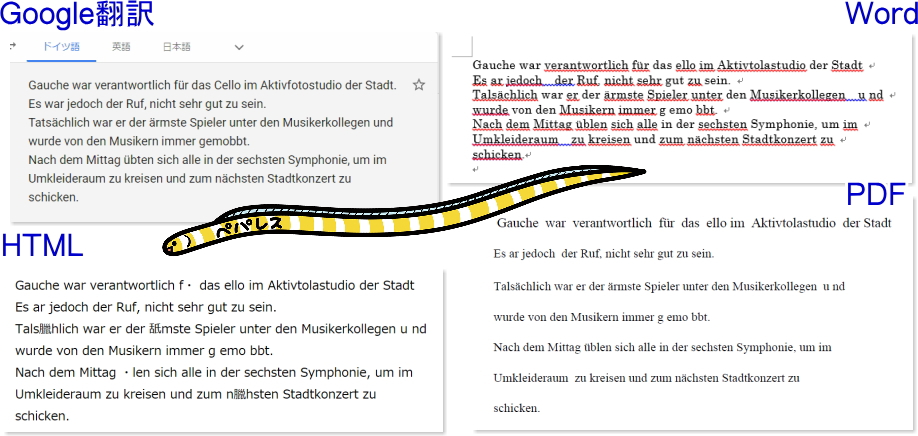
Webブラウザ(HTML)では、「ä」「ü」などの特殊な形のアルファベットが「・」や漢字に文字化けしています。WordやPDFでは問題なく表示されています。
・ロシア語
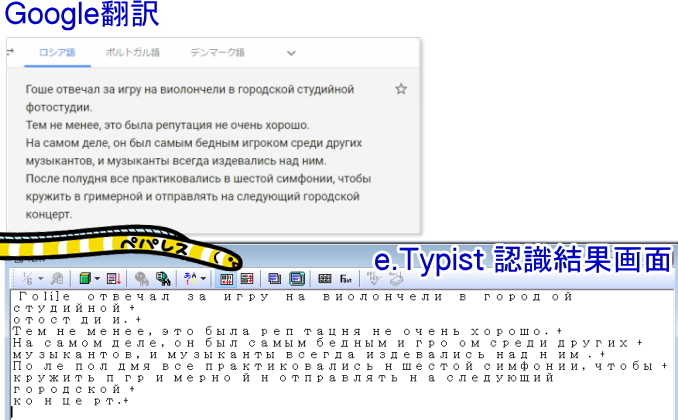

認識結果の画面では、文字セットをキリル言語にするとこのように表示されました。
しかし、Word、HTML、PDFでは全く異なる言語に文字化けしています。
【欧米言語(その他)】
Google翻訳に登録されていない言語(アイマラ語、ブルトン語、フラマン語、ニュージーランド英語、セルボクロアチア語、タヒチ語、フェロー語、フリウリ語、グリーンランド語、南ソルビア語、北ソルビア語)
は、Wikipediaなどの言語が載っているページのスクリーンショットを利用してOCR認識を行いました。
全体的に日本語、英語、欧米言語と比較すると、認識精度が少し劣っているように感じます。
キリル言語、ギリシャ語はロシア語と同様、外部へ転送すると全て文字化けするという結果になりました。
また、認識精度が50%にも満たない言語も一部ありました。
なお、アイマラ語、フリウリ語は出来る限り検索したものの、文例が見つからず検証できませんでした。
しかし、どちらもラテン文字が基本のようなので、OCR認識はある程度可能と考えられます。
・ギリシア語
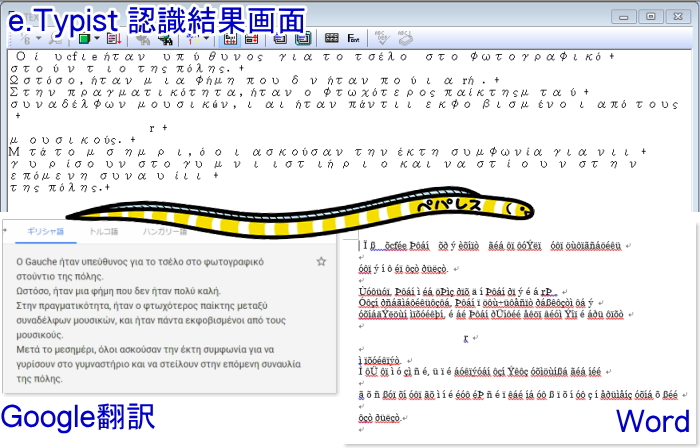
ギリシア語は独特の文字の形をしていますが、これも文字セットに「ギリシャ語」があるので、その設定で文字化けは回避できました。
しかし、外部へ出力すると文字化けします。
・セルビア語
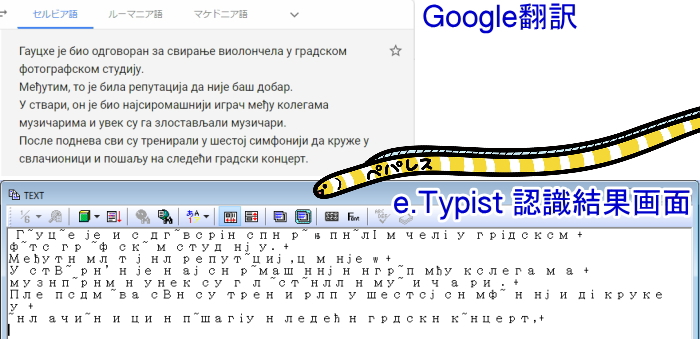
セルビア語は文字セットをキリル言語にすると文字化けがなくなったように見えましたが、一部の文字は「~」に置き換えられています。
表記体系がキリル文字とラテン文字なので、ラテン文字が文字化けの原因になっているのではないかと考えられます。
WordやPDFに出力すると全て文字化けしてしまうので、正常な状態の認識結果を表示することは不可能でした。
・フェロー語

引用元:ウィキトラベル会話集
フェロー語は消滅危険度評価が「脆弱」とされている言語で、珍しい形の文字があるせいか認識精度が低いという結果になりました。
・グリーンランド語

引用元:Wikipedia
グリーンランド語は基本的に一般的なラテン文字を使用した言語ですが、「n」や「m」が連続で羅列している箇所が多く、それらが誤認識の原因となっているように感じました。
【アジア言語】
アジア言語は、WordとExcel以外への転送はソフトの仕様上不可能でした。
認識精度は△としていますが、中国語は文字の画数が多いため、高解像度の白黒2値の画像であれば認識精度の向上も見込めるかと思います。
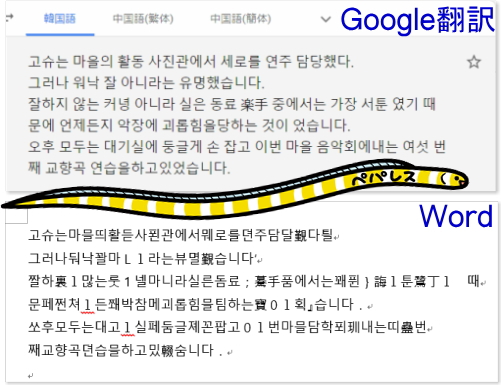
また、ハングル文字は基本的に正確に表示されていますが、認識結果には漢字がいくつか混ざっていました。
Wordへ転送しても修正されなかったので、文字化けではなくバグと考えられます。
・簡体字
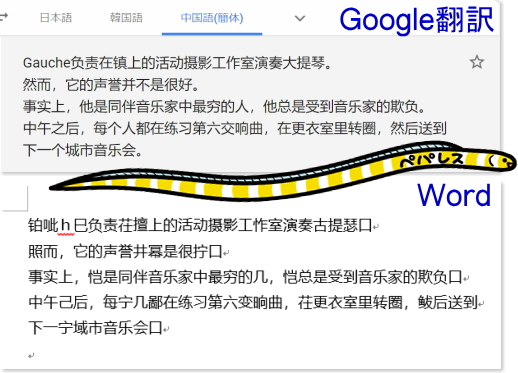
・韓国語
以上が全ての検証結果です。
総合して要点をまとめると
となりました。
冒頭にも記したように、この検証は最新のバージョンでは行っていないため、現在ではバグが解消されている箇所もあると思われます。
e.Typistには一定期間無料で使用できる体験版がありますので、この記事を参考に更に検証・購入を検討される場合は、そちらを利用してみてください。
弊社のOCRサービスは基本的に日本語と英語を対象としていますが、このe.Typistも所有しておりますので、その他の言語でのOCR化を希望される方は是非一度ご相談ください。
OCRソフト「e.Typist」 58か国語の検証
近年ではインターネットの普及やグローバル化の影響で、英語を含む様々な言語を利用する人も増加傾向にあります。
この数年で翻訳ツールが増加して精度も向上していますが、それらのツールを利用する場合、大抵はテキスト情報を入力する必要があります。
そのテキスト情報を書籍や書類などの紙媒体から抽出するのがOCRソフトの役目なのですが、殆どのソフトは英語と日本語しか認識できません。
それ以外の幅広い言語に対応しているOCRソフトの1つが、株式会社エヌジェーケーから販売されている「活字OCRソフト e.Typist」です。
初代が1995年発売というロングセラーのソフトで、対応言語は58か国語です。
世界に存在する言語の数は数千種類とも言われていますが、これだけあれば主要なものはほぼ対応していると思われます。
e.TypistではOCR認識を行ったあと、PDFやWord、Excelへ転送したり、Webブラウザで開いたりすることができます。
日本語や英語以外の言語を利用されている方にとっては唯一無二の大変助かるツールになり得ます。
この度ペパレスでは58か国語全てでOCR認識を行い、
| 1. 正確にOCR認識できているのか? 2. それぞれの言語でどの転送が可能なのか?正確に転送されているのか? |
について検証しました。
検証の流れは
| 1. 例文を用意し、Googleの翻訳機能を使ってそれぞれの言語で翻訳 2. スクリーンショットで翻訳結果を画像化 3. 画像化された翻訳文をOCR認識 4. 外部へ出力し、実際の文章とOCR結果を比較 |
としています。
また、これは認識精度の検証を目的としていますので、翻訳結果に誤りがある可能性があります。
その点はご了承ください。
なお、検証は「e.Typist v.12.0」で行いました。
最新のバージョン「e.Typist v.15.0」とは異なる部分もあると考えられます。その点を踏まえたうえで、参考にしてください。
①「e.Typist」 58か国語の対応言語一覧
| 日本語、英語 | |
| 欧米言語 | ドイツ語、フランス語、スペイン語、イタリア語、オランダ語、スウェーデン語、ノルウェー語、フィンランド語、デンマーク語、ポルトガル語、ロシア語 |
| 欧米言語(その他) | ポーランド語、チェコ語、ハンガリー語、トルコ語、ギリシア語、アフリカーンス語、アルバニア語、アイマラ語、バスク語、ブルトン語、ブルガリア語、カタロニア語、クロアチア語、エストニア語、フラマン語、ゲール語、ハワイ語、アイスランド語、ラテン語、ラトビア語、リトアニア語、マケドニア語、英語(ニュージーランド)、ルーマニア語、セルビア語、セルボクロアチア語、スロバキア語、スロベニア語、スワヒリ語、タヒチ語、ウクライナ語、ウェールズ語、西フリースランド語、ズールー語、ベラルーシ語、フェロー語、フリウリ語、グリーンランド語、インドネシア語、クルド語、南ソルビア語、マレー語、北ソルビア語 |
| アジア系言語 | 中国語(簡体/繁体)、韓国語 |
Google翻訳で対応していない言語も同様です。
ニュージーランド英語は英語のバリエーションの一つで、綴りはイギリス英語式ですが、独特のイントネーションや語彙があります。よって、一般的な英語とは区別されています。
②OCR認識結果の文字化けを防ぐ
様々な言語をOCRするとなると、日本語やラテン文字以外も文字も勿論対象となります。
しかし、e.Typistの初期設定では、欧米言語は一般的なラテン文字以外が文字化けして表示されます。
文字化けはバグと勘違いされてしまうケースも少なくないと思いますが、このソフトでは設定で対処できます。
手順は次の通りです。
「ツール」→「環境設定」→「フォント」→「表示フォント設定」→「文字セット」
文字セットは日本語、欧文、ギリシャ語、トルコ語、バルト諸国言語、中央ヨーロッパ言語、キリル言語から選択できます。
認識結果に文字化けが生じている場合、この文字セットを適切なものにすると殆どの場合は解消されます。
例として、フィンランド語のOCR認識結果をご覧ください。
初期設定では文字化けがありましたが、文字セットを「欧文」に設定するとこのように修正されました。
③OCR認識と出力 結果一覧
では、本題の検証結果です。
実際にOCR認識を行った結果を、言語のカテゴリー毎にまとめました。
認識精度に加え、出力形式の検証はWord、HTML、PDF(分かりやすくするため、形式は認識結果PDF)の3つとします。
基本的には同じ例文を使用していますが、Google翻訳が対応していないものは、Wikipediaなど他のWebサイトから画像をお借りしてOCR認識を行いました。
評価は○、△、×の三段階で
○…認識精度80%以上/正確に表示
△…認識精度50~79%/一部文字化け
×…認識精度50%未満/全て文字化け
としています。
【例文】宮沢賢治『セロ弾きのゴーシュ』より引用
| ゴーシュは町の活動写真館でセロを弾く係りでした。 けれどもあんまり上手でないという評判でした。 上手でないどころではなく実は仲間の楽手のなかではいちばん下手でしたから、いつでも楽長にいじめられるのでした。 昼過ぎみんなは楽屋に円くならんで今度の町の音楽会へ出す第六交響曲の練習をしていました。 |
【日本語・英語】
| 言語 | 認識精度 | Word | HTML | |
| 日本語 | ○ | ○ | ○ | ○ |
| 英語 | ○ | ○ | ○ | ○ |
一部誤認識はありましたが、殆どは正確にOCR認識されました。
いずれもWord、HTML、PDF、それぞれに出力することもできました。
・日本語
・英語
【欧米言語】
| 言語 | 認識精度 | Word | HTML | |
| ドイツ語 | ○ | ○ | △ | ○ |
| フランス語 | ○ | ○ | △ | ○ |
| スペイン語 | ○ | ○ | △ | ○ |
| イタリア語 | ○ | ○ | △ | ○ |
| オランダ語 | ○ | ○ | ○ | ○ |
| スウェーデン語 | ○ | ○ | △ | ○ |
| ノルウェー語 | ○ | ○ | △ | ○ |
| フィンランド語 | ○ | ○ | △ | ○ |
| デンマーク語 | ○ | ○ | △ | ○ |
| ポルトガル語 | ○ | ○ | △ | ○ |
| ロシア語 | ○ | × | × | × |
認識精度は全て問題ないと言えるレベルでした。
ロシア語以外WordやPDFへの転送も問題ありませんでしたが、Webブラウザでは文字化けするものが多かったです。
ロシア語は出力すると、全て文字化けしてしまいました。
全ての言語でそれぞれの出力結果を掲載すると膨大な画像の量になりますので、画像はポイントを絞ってあげています。
・ドイツ語
Webブラウザ(HTML)では、「ä」「ü」などの特殊な形のアルファベットが「・」や漢字に文字化けしています。WordやPDFでは問題なく表示されています。
・ロシア語
認識結果の画面では、文字セットをキリル言語にするとこのように表示されました。
しかし、Word、HTML、PDFでは全く異なる言語に文字化けしています。
【欧米言語(その他)】
| 言語 | 認識精度 | Word | HTML | |
| ポーランド語 | △ | △ | △ | △ |
| チェコ語 | ○ | ○ | △ | ○ |
| ハンガリー語 | ○ | ○ | △ | ○ |
| トルコ語 | ○ | ○ | △ | ○ |
| ギリシア語 | ○ | × | × | × |
| アフリカーンス語 | ○ | ○ | ○ | ○ |
| アルバニア語 | ○ | ○ | △ | ○ |
| アイマラ語 | - | - | - | - |
| バスク語 | ○ | ○ | ○ | ○ |
| ブルトン語 | ○ | ○ | ○ | ○ |
| ブルガリア語 | △ | × | × | × |
| カタロニア語 | ○ | ○ | △ | ○ |
| クロアチア語 | △ | ○ | △ | ○ |
| エストニア語 | ○ | ○ | △ | ○ |
| フラマン語 | △ | ○ | △ | ○ | >
| ゲール語(スコットランド) | △ | ○ | △ | ○ |
| ゲール語(アイルランド) | ○ | ○ | △ | ○ |
| ハワイ語 | △ | △ | △ | △ |
| アイスランド語 | △ | △ | △ | △ |
| ラテン語 | ○ | ○ | ○ | ○ |
| ラトビア語 | △ | ○ | △ | ○ |
| リトアニア語 | △ | △ | △ | △ |
| マケドニア語 | △ | × | × | × |
| 英語(ニュージーランド) | ○ | ○ | ○ | ○ |
| ルーマニア語 | △ | △ | △ | △ |
| セルビア語 | × | × | × | × |
| セルボクロアチア語 | △ | ○ | △ | ○ |
| スロバキア語 | △ | ○ | △ | ○ |
| スロベニア語 | ○ | ○ | △ | ○ |
| スワヒリ語 | ○ | ○ | ○ | ○ |
| タヒチ語 | △ | ○ | ○ | ○ |
| ウクライナ語 | × | × | × | × |
| ウェールズ語 | ○ | ○ | ○ | ○ |
| 西フリースランド語(フリジア語) | ○ | ○ | △ | ○ |
| ズールー語 | △ | ○ | ○ | ○ |
| ベラルーシ語 | △ | × | × | × |
| フェロー語 | × | ○ | △ | ○ |
| フリウリ語 | - | - | - | - |
| グリーンランド語 | × | ○ | △ | ○ |
| インドネシア語 | ○ | ○ | ○ | ○ |
| クルド語 | △ | ○ | △ | ○ |
| 南ソルビア語(低地ソルブ語) | × | ○ | △ | ○ |
| マレー語 | ○ | ○ | ○ | ○ |
| 北ソルビア語(高地ソルブ語) | △ | ○ | △ | ○ |
Google翻訳に登録されていない言語(アイマラ語、ブルトン語、フラマン語、ニュージーランド英語、セルボクロアチア語、タヒチ語、フェロー語、フリウリ語、グリーンランド語、南ソルビア語、北ソルビア語)
は、Wikipediaなどの言語が載っているページのスクリーンショットを利用してOCR認識を行いました。
全体的に日本語、英語、欧米言語と比較すると、認識精度が少し劣っているように感じます。
キリル言語、ギリシャ語はロシア語と同様、外部へ転送すると全て文字化けするという結果になりました。
また、認識精度が50%にも満たない言語も一部ありました。
なお、アイマラ語、フリウリ語は出来る限り検索したものの、文例が見つからず検証できませんでした。
しかし、どちらもラテン文字が基本のようなので、OCR認識はある程度可能と考えられます。
・ギリシア語
ギリシア語は独特の文字の形をしていますが、これも文字セットに「ギリシャ語」があるので、その設定で文字化けは回避できました。
しかし、外部へ出力すると文字化けします。
・セルビア語
セルビア語は文字セットをキリル言語にすると文字化けがなくなったように見えましたが、一部の文字は「~」に置き換えられています。
表記体系がキリル文字とラテン文字なので、ラテン文字が文字化けの原因になっているのではないかと考えられます。
WordやPDFに出力すると全て文字化けしてしまうので、正常な状態の認識結果を表示することは不可能でした。
・フェロー語
引用元:ウィキトラベル会話集
フェロー語は消滅危険度評価が「脆弱」とされている言語で、珍しい形の文字があるせいか認識精度が低いという結果になりました。
・グリーンランド語
引用元:Wikipedia
グリーンランド語は基本的に一般的なラテン文字を使用した言語ですが、「n」や「m」が連続で羅列している箇所が多く、それらが誤認識の原因となっているように感じました。
【アジア言語】
| 言語 | 認識精度 | Word | HTML | |
| 中国語(簡体) | △ | ○ | × | × |
| 中国語(繁体) | △ | ○ | × | × |
| 韓国語 | △ | △ | × | × |
アジア言語は、WordとExcel以外への転送はソフトの仕様上不可能でした。
認識精度は△としていますが、中国語は文字の画数が多いため、高解像度の白黒2値の画像であれば認識精度の向上も見込めるかと思います。
また、ハングル文字は基本的に正確に表示されていますが、認識結果には漢字がいくつか混ざっていました。
Wordへ転送しても修正されなかったので、文字化けではなくバグと考えられます。
・簡体字
・韓国語
以上が全ての検証結果です。
総合して要点をまとめると
| ・ 日本語、英語、欧米言語のカテゴリーは認識精度が高い ・ 特殊な形状のラテン文字はWordやPDFへの転送は可能だが、HTMLでは文字化けする ・ キリル言語、ギリシャ語はOCR認識できるが、外部へ転送すると全て文字化けする ・ アジア言語はWord、Excel以外に転送できない |
となりました。
冒頭にも記したように、この検証は最新のバージョンでは行っていないため、現在ではバグが解消されている箇所もあると思われます。
e.Typistには一定期間無料で使用できる体験版がありますので、この記事を参考に更に検証・購入を検討される場合は、そちらを利用してみてください。
弊社のOCRサービスは基本的に日本語と英語を対象としていますが、このe.Typistも所有しておりますので、その他の言語でのOCR化を希望される方は是非一度ご相談ください。