ペパレス > コラムTOP > 白背景イメージと黒背景イメージ
国内外問わず、現在では様々な企業からOCRソフトが販売されています。
無料で提供されているものも多く、使用した感想をまとめたコラムページも多数存在します。
しかし、王道とされるOCRソフトは1万円を超える価格で敷居が高く、文字認識を行うデータや用途に合わせて慎重にソフトを選択する必要があります。
ペパレスのホームページをご覧になられた方は大半がPDFの電子書籍を利用されていることと思いますので、PDFファイルを使用してOCRソフトの比較を行います。
比較するのは、検索エンジンでOCRソフトと入力すると上位に上がる
・Panasonic「読取革命」
・株式会社エヌジェーケー「e.Typist」
・Adobe「Acrobat Pro」
・Google 「Googleドキュメント」
の4つとします。
比較する項目は
・精度
・認識時間
・対応言語
・入力・出力形式
・ファイルサイズ(PDF)
そして、それぞれのソフトに適している用途や対象をまとめていきます。
精度は同じサンプルのPDFをOCR化してテキストのみを抽出し、Wordの比較機能で本来のテキストと比較して「変更箇所」の数を元に算出しています。
ファイルサイズ: 1,043KB 文字数:1412文字 画像:5枚 フローチャート(網かけ):2箇所


OCRソフトと言えば、この「読取革命」は外せない存在です。
搭載されている全ての機能を使いこなすのは寧ろ困難、と思えるほど多彩な用途に対応できるソフトです。
国内大手企業であるPanasonicから販売されているという信頼感もあります。
〇精度 約98%:誤認識 29箇所(内、画像3枚)
数字を見れば精度は高いですが、40%の網かけを画像として認識してしまったために、中に書かれている文章はテキスト化されませんでした。
逆に画像を文字として誤認識してしまった箇所もありましたが、手動で認識箇所のレイアウトを作成したり、画像を白黒2値に減色したりすることもできるソフトなので、手間をかければほぼ完璧なOCR処理が可能です。
〇認識時間 約6秒
〇対応言語 日本語、英語
認識にも日本語モードと英語モードの2つがあります。英語モードは英数字専用の読み取りですが、自動認識でもかなり精度が高い印象です。
〇入力・出力形式
・入力形式
PDF、BMP、TIFF、JPEG、GIFなどの36種類の画像ファイル
モバイルデバイス、デジタルカメラ、スキャナー、複合機、ビデオカメラ、画面キャプチャー
・出力形式
Word、Excel、PowerPoint、XPS、PDF、一太郎、HTML、XML、RTF、CSV、TXTなど18種類
入力、出力ともに対応している形式が最も多い結果となりました。モバイルデバイスから読み込めるのも特徴と言えます。
〇ファイルサイズ(PDF)
最低:647KB 標準:888KB 高画質:1,314KB 最高画質:2,688KB
出力するPDFのファイルサイズが4パターンあるので、用途やスペックに合わせて画質を選択できます。
〇まとめ
OCRソフトのトップ的存在なだけあって、精度や汎用性も高い結果となりました。
認識結果を一文字ずつ修正できる機能も搭載されているので、
・正確なOCR処理を行いたい方
・様々なファイル形式でOCR機能を使用したい方
・高画質で透明文字埋め込みPDFを作成したい方
にオススメです。
画像の修正機能などその他様々な機能も搭載されているので、OCRをよく利用するならば買って損はないと言える高性能なソフトです。

価格は高いですが、読取革命に匹敵する人気のOCRソフトです。多くの言語に対応していることが一番の特徴です。
価格が低いバージョンも存在しますが、ここでは上のグレードのものを比較対象とします。
〇精度 約96%:誤認識 59箇所(内、画像2枚)
2行を1行として誤認識した箇所、画像を文字として誤認識した箇所があり、誤認識の数は読取革命の倍となりました。ただし、網かけの中の文字は正常に認識されています。
こちらのソフトも認識エリアを手動で設定する、画像を白黒2値に減色することができるので、レイアウトのミスを回避すれば精度の更なる向上も期待できます
〇認識時間 約2秒
この度の検証では、認識速度は最速です。
〇対応言語 日本、欧米、中国、ハングルなど58カ国語に対応
OCRソフトの中では、最も多くの言語に対応しているソフトであると考えられます。
〇入力・出力形式
・入力形式
PDF、BMP、TIFF、JPEG、PNG、XDW
デジタルカメラ、スキャナー
・出力形式
TEXT、CSV、RTF、Word、Excel、PowerPoint、一太郎、PDF、HTML、XHTML、XDW、XPS、EPUB
外部クラウドサービス:Evernote/Dropbox/SugarSync/SkyDrive(データ転送)
iPhone/Androidアプリ:DocMobile(データ転送)
対応している形式の種類は読取革命に劣りますが、クラウドサービスやアプリへデータ転送ができる機能は他のOCRソフトにはありません。
この機能を使用すれば、PC、スマートフォン、タブレットで簡単にデータを共有できます。
〇ファイルサイズ(PDF)
コンパクト:282KB 標準:1,333KB きれい:3,982KB
出力できるファイルサイズの種類は3パターンですが、それぞれのサイズは大きく異なるので、こちらも用途に合った画質の選択ができます。
〇まとめ
読取革命と同様に機能が充実しているソフトなので、幅広い用途に対応しています。
e.Typistにしかない特徴を踏まえると、
・日本語、英語以外の言語でOCR処理を行いたい方
・PC以外の端末へ手軽にファイルを共有したい方
・高画質で透明文字埋め込みPDFを作成したい方
にオススメです。
処理速度は比較した中で最速だったため、ページ数の多いファイルを使用する機会が多い方にも適しています。

有料のものに限りますが、Acrobat自体にもOCR機能が搭載されています。
AcrobatのOCR機能で事足りるのであれば、わざわざOCRソフトを購入する必要もありません。
ここではAcrobat Proを比較対象としていますが、Acrobat StandardでもOCR機能は搭載されています。
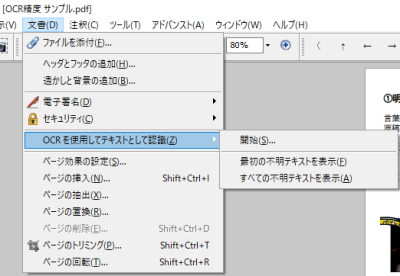
文書タブから「OCRを使用してテキストとして認識」を選択すると認識が開始されます。スキャナーから読み込むと同時にOCRを行うこともできます。
〇精度 約95%:誤認識 70箇所(内、画像3枚)
文字の認識精度はOCR専用のソフトに比べ、大きく劣ることはありませんでした。
グレーの網かけの中の文字は正常に認識した半面、水色の網かけの中の文字は誤認識が目立ちました。
画像は認識しない仕様となっているため、文字として誤認識されている箇所が3箇所という結果になりました。
〇認識時間 約8秒
〇対応言語 日本語、英語
日本語モードでは日本語、英語の両方が認識されます。
英語モードで認識した場合は読取革命と同様に英数字のみの認識となりますが、スペルチェックが自動で行われるのでかなりの高精度になります。
ただし、Acrobat7.0 Standardで検証したところ、対応言語は日本語のみでした。バージョンによって仕様が異なるかもしれませんが、Acrobat Proであれば確実に英語モードを選択できます。
〇入力・出力形式
・入力形式
PDF、スキャナー
・出力形式
PDF
〇ファイルサイズ(PDF)
ダウンサンプリング
高(72dpi):99KB 中(150dpi):244KB 低(300dpi):680KB 最低(600dpi):680KB
低と最低は同じファイルサイズになりましたが、これは元々のPDFの解像度が300dpiだったことが原因と考えられます。
ただし、ダウンサンプリングの影響で全体的にファイルサイズが小さくなっています。それに伴って文字や画像も強い圧縮がかかり、画質の劣化が目立ちます。
〇まとめ
OCR専用のソフトではありませんが、精度が著しく低いということはありません。
ただし文字認識には負荷がかかり、Acrobatが動作を停止する場合もあるので注意が必要です。
・PDFの文字検索をメインとして使いたい方
・PDF以外でOCRしたデータを使用しない方
は、AcrobatのOCR機能で差し支えはないかと思います。

フリーでOCR機能を利用する場合、検索してまず目にするのはこの「Googleドキュメント」です。
有料のソフトとは仕様や用途が異なる点もありますが、OCRソフトの購入を検討するには、無料で出来るOCR処理も知っておく必要があります。
〇精度 約96.5%:誤認識 49箇所(内、画像4枚)
認識精度は読取革命に次ぐものとなりました。グレーと水色の網かけ、共に問題なく文字を認識しています。
Acrobatと同様に文字のみを認識する仕様なので、画像を文字として誤認識したのが4箇所という結果になりました。
〇認識時間 約10秒
〇対応言語 48カ国語
現在の対応言語は48カ国語となっており、日本語は2007年から対応されました。翻訳機能もあります。
〇入力・出力形式
・入力形式
PDF 、JPEG、PNG、GIF、Word、Excel、PowerPoint、HTML、ODT、RTF、TXT、ODS、CSV、TSV、TAB、PPS
・出力形式
PDF、JPEG、PNG、Word、Excel、PowerPoint、HTML、ODT、RTF、TXT、ODS、CSV、TSV、TAB、PPS、SVG
よく使われる形式は採用されています。
ただし、出力されるPDFは透明文字が埋め込まれたものでなく、テキスト化されたOCR結果が文書の状態でPDFとして書き出されたものとなります。
〇ファイルサイズ(PDF)
769KB
〇まとめ
透明文字付きのPDFは作成できませんが、画像の文字を高精度でテキスト化することができます。
・画像内のテキストを引用したい方
・画像内のテキストを別のファイル形式で出力したい方
は、まず無料であるGoogleドキュメントを使用してから他のソフトの利用を検討して良いかと思います。
特に論文や資料作成を低コストで行いたい方には最適です。
Googleドライブと連結しているので、ログインした端末であれば場所を問わずデータを閲覧できることも特徴の一つです。
最後になりましたが、比較結果を表にまとめたものです。
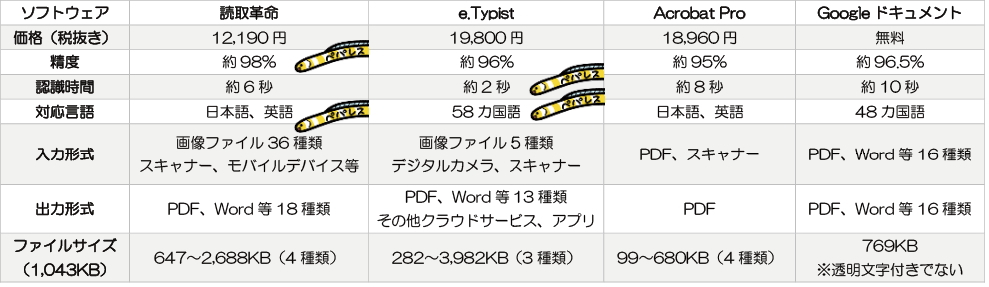
4つのOCRサービスを具体的に比較しましたが、OCR専門の有料ソフトは機能が多いため用途の幅が広く、仕上がるファイルも品質が高いという結果になりました。
手動で校正することもできるので、手間をかければほぼ完璧なOCR処理が実現します。
読取革命、e.Typistには共通点も多くありますが、それぞれにしかない特徴も記載しましたので、購入を考えている方は参考にしてみてください。
AcrobatやGoogleドキュメントは有料のOCRソフトには汎用性の面で劣りますが、精度は高いため、用途によってはこれらでも問題なく目的を果たす事はできます。
また、単発的に本格的なOCR処理を行いたい場合、読取革命、e.Typist、Acrobat Pro、それぞれに無料体験版が存在しますので、そちらをインストールして利用することも方法の一つです。
ペパレスでも1冊800円~OCR処理を行うサービスがありますので、機会があればご利用ください。
OCRソフトの比較
国内外問わず、現在では様々な企業からOCRソフトが販売されています。
無料で提供されているものも多く、使用した感想をまとめたコラムページも多数存在します。
しかし、王道とされるOCRソフトは1万円を超える価格で敷居が高く、文字認識を行うデータや用途に合わせて慎重にソフトを選択する必要があります。
ペパレスのホームページをご覧になられた方は大半がPDFの電子書籍を利用されていることと思いますので、PDFファイルを使用してOCRソフトの比較を行います。
比較するのは、検索エンジンでOCRソフトと入力すると上位に上がる
・Panasonic「読取革命」
・株式会社エヌジェーケー「e.Typist」
・Adobe「Acrobat Pro」
・Google 「Googleドキュメント」
の4つとします。
比較する項目は
・精度
・認識時間
・対応言語
・入力・出力形式
・ファイルサイズ(PDF)
そして、それぞれのソフトに適している用途や対象をまとめていきます。
精度は同じサンプルのPDFをOCR化してテキストのみを抽出し、Wordの比較機能で本来のテキストと比較して「変更箇所」の数を元に算出しています。
サンプルデータ情報
ファイルサイズ: 1,043KB 文字数:1412文字 画像:5枚 フローチャート(網かけ):2箇所
Panasonic「読取革命」 12,190円 (税抜)
OCRソフトと言えば、この「読取革命」は外せない存在です。
搭載されている全ての機能を使いこなすのは寧ろ困難、と思えるほど多彩な用途に対応できるソフトです。
国内大手企業であるPanasonicから販売されているという信頼感もあります。
〇精度 約98%:誤認識 29箇所(内、画像3枚)
数字を見れば精度は高いですが、40%の網かけを画像として認識してしまったために、中に書かれている文章はテキスト化されませんでした。
逆に画像を文字として誤認識してしまった箇所もありましたが、手動で認識箇所のレイアウトを作成したり、画像を白黒2値に減色したりすることもできるソフトなので、手間をかければほぼ完璧なOCR処理が可能です。
〇認識時間 約6秒
〇対応言語 日本語、英語
認識にも日本語モードと英語モードの2つがあります。英語モードは英数字専用の読み取りですが、自動認識でもかなり精度が高い印象です。
〇入力・出力形式
・入力形式
PDF、BMP、TIFF、JPEG、GIFなどの36種類の画像ファイル
モバイルデバイス、デジタルカメラ、スキャナー、複合機、ビデオカメラ、画面キャプチャー
・出力形式
Word、Excel、PowerPoint、XPS、PDF、一太郎、HTML、XML、RTF、CSV、TXTなど18種類
入力、出力ともに対応している形式が最も多い結果となりました。モバイルデバイスから読み込めるのも特徴と言えます。
〇ファイルサイズ(PDF)
最低:647KB 標準:888KB 高画質:1,314KB 最高画質:2,688KB
出力するPDFのファイルサイズが4パターンあるので、用途やスペックに合わせて画質を選択できます。
〇まとめ
OCRソフトのトップ的存在なだけあって、精度や汎用性も高い結果となりました。
認識結果を一文字ずつ修正できる機能も搭載されているので、
・正確なOCR処理を行いたい方
・様々なファイル形式でOCR機能を使用したい方
・高画質で透明文字埋め込みPDFを作成したい方
にオススメです。
画像の修正機能などその他様々な機能も搭載されているので、OCRをよく利用するならば買って損はないと言える高性能なソフトです。
株式会社エヌジェーケー「e.Typist」 19,800円(税別)
価格は高いですが、読取革命に匹敵する人気のOCRソフトです。多くの言語に対応していることが一番の特徴です。
価格が低いバージョンも存在しますが、ここでは上のグレードのものを比較対象とします。
〇精度 約96%:誤認識 59箇所(内、画像2枚)
2行を1行として誤認識した箇所、画像を文字として誤認識した箇所があり、誤認識の数は読取革命の倍となりました。ただし、網かけの中の文字は正常に認識されています。
こちらのソフトも認識エリアを手動で設定する、画像を白黒2値に減色することができるので、レイアウトのミスを回避すれば精度の更なる向上も期待できます
〇認識時間 約2秒
この度の検証では、認識速度は最速です。
〇対応言語 日本、欧米、中国、ハングルなど58カ国語に対応
OCRソフトの中では、最も多くの言語に対応しているソフトであると考えられます。
〇入力・出力形式
・入力形式
PDF、BMP、TIFF、JPEG、PNG、XDW
デジタルカメラ、スキャナー
・出力形式
TEXT、CSV、RTF、Word、Excel、PowerPoint、一太郎、PDF、HTML、XHTML、XDW、XPS、EPUB
外部クラウドサービス:Evernote/Dropbox/SugarSync/SkyDrive(データ転送)
iPhone/Androidアプリ:DocMobile(データ転送)
対応している形式の種類は読取革命に劣りますが、クラウドサービスやアプリへデータ転送ができる機能は他のOCRソフトにはありません。
この機能を使用すれば、PC、スマートフォン、タブレットで簡単にデータを共有できます。
〇ファイルサイズ(PDF)
コンパクト:282KB 標準:1,333KB きれい:3,982KB
出力できるファイルサイズの種類は3パターンですが、それぞれのサイズは大きく異なるので、こちらも用途に合った画質の選択ができます。
〇まとめ
読取革命と同様に機能が充実しているソフトなので、幅広い用途に対応しています。
e.Typistにしかない特徴を踏まえると、
・日本語、英語以外の言語でOCR処理を行いたい方
・PC以外の端末へ手軽にファイルを共有したい方
・高画質で透明文字埋め込みPDFを作成したい方
にオススメです。
処理速度は比較した中で最速だったため、ページ数の多いファイルを使用する機会が多い方にも適しています。
Adobe「Acrobat Pro」 18,960円(税別)
有料のものに限りますが、Acrobat自体にもOCR機能が搭載されています。
AcrobatのOCR機能で事足りるのであれば、わざわざOCRソフトを購入する必要もありません。
ここではAcrobat Proを比較対象としていますが、Acrobat StandardでもOCR機能は搭載されています。
文書タブから「OCRを使用してテキストとして認識」を選択すると認識が開始されます。スキャナーから読み込むと同時にOCRを行うこともできます。
〇精度 約95%:誤認識 70箇所(内、画像3枚)
文字の認識精度はOCR専用のソフトに比べ、大きく劣ることはありませんでした。
グレーの網かけの中の文字は正常に認識した半面、水色の網かけの中の文字は誤認識が目立ちました。
画像は認識しない仕様となっているため、文字として誤認識されている箇所が3箇所という結果になりました。
〇認識時間 約8秒
〇対応言語 日本語、英語
日本語モードでは日本語、英語の両方が認識されます。
英語モードで認識した場合は読取革命と同様に英数字のみの認識となりますが、スペルチェックが自動で行われるのでかなりの高精度になります。
ただし、Acrobat7.0 Standardで検証したところ、対応言語は日本語のみでした。バージョンによって仕様が異なるかもしれませんが、Acrobat Proであれば確実に英語モードを選択できます。
〇入力・出力形式
・入力形式
PDF、スキャナー
・出力形式
〇ファイルサイズ(PDF)
ダウンサンプリング
高(72dpi):99KB 中(150dpi):244KB 低(300dpi):680KB 最低(600dpi):680KB
低と最低は同じファイルサイズになりましたが、これは元々のPDFの解像度が300dpiだったことが原因と考えられます。
ただし、ダウンサンプリングの影響で全体的にファイルサイズが小さくなっています。それに伴って文字や画像も強い圧縮がかかり、画質の劣化が目立ちます。
〇まとめ
OCR専用のソフトではありませんが、精度が著しく低いということはありません。
ただし文字認識には負荷がかかり、Acrobatが動作を停止する場合もあるので注意が必要です。
・PDFの文字検索をメインとして使いたい方
・PDF以外でOCRしたデータを使用しない方
は、AcrobatのOCR機能で差し支えはないかと思います。
Google 「Googleドキュメント」 無料
フリーでOCR機能を利用する場合、検索してまず目にするのはこの「Googleドキュメント」です。
有料のソフトとは仕様や用途が異なる点もありますが、OCRソフトの購入を検討するには、無料で出来るOCR処理も知っておく必要があります。
〇精度 約96.5%:誤認識 49箇所(内、画像4枚)
認識精度は読取革命に次ぐものとなりました。グレーと水色の網かけ、共に問題なく文字を認識しています。
Acrobatと同様に文字のみを認識する仕様なので、画像を文字として誤認識したのが4箇所という結果になりました。
〇認識時間 約10秒
〇対応言語 48カ国語
現在の対応言語は48カ国語となっており、日本語は2007年から対応されました。翻訳機能もあります。
〇入力・出力形式
・入力形式
PDF 、JPEG、PNG、GIF、Word、Excel、PowerPoint、HTML、ODT、RTF、TXT、ODS、CSV、TSV、TAB、PPS
・出力形式
PDF、JPEG、PNG、Word、Excel、PowerPoint、HTML、ODT、RTF、TXT、ODS、CSV、TSV、TAB、PPS、SVG
よく使われる形式は採用されています。
ただし、出力されるPDFは透明文字が埋め込まれたものでなく、テキスト化されたOCR結果が文書の状態でPDFとして書き出されたものとなります。
〇ファイルサイズ(PDF)
769KB
〇まとめ
透明文字付きのPDFは作成できませんが、画像の文字を高精度でテキスト化することができます。
・画像内のテキストを引用したい方
・画像内のテキストを別のファイル形式で出力したい方
は、まず無料であるGoogleドキュメントを使用してから他のソフトの利用を検討して良いかと思います。
特に論文や資料作成を低コストで行いたい方には最適です。
Googleドライブと連結しているので、ログインした端末であれば場所を問わずデータを閲覧できることも特徴の一つです。
最後になりましたが、比較結果を表にまとめたものです。
4つのOCRサービスを具体的に比較しましたが、OCR専門の有料ソフトは機能が多いため用途の幅が広く、仕上がるファイルも品質が高いという結果になりました。
手動で校正することもできるので、手間をかければほぼ完璧なOCR処理が実現します。
読取革命、e.Typistには共通点も多くありますが、それぞれにしかない特徴も記載しましたので、購入を考えている方は参考にしてみてください。
AcrobatやGoogleドキュメントは有料のOCRソフトには汎用性の面で劣りますが、精度は高いため、用途によってはこれらでも問題なく目的を果たす事はできます。
また、単発的に本格的なOCR処理を行いたい場合、読取革命、e.Typist、Acrobat Pro、それぞれに無料体験版が存在しますので、そちらをインストールして利用することも方法の一つです。
ペパレスでも1冊800円~OCR処理を行うサービスがありますので、機会があればご利用ください。