ペパレス > コラムTOP > 本の部位の名称
本には、あらゆる部位に名称がついています。
表紙や帯など一般的に知られている名称もありますが、本を手に取る機会が多い方の中でも、その詳細を知る人はおそらく限られていることと思います。
ホームページやお問い合わせにてサービスの詳細をお伝えする際、本の各部位を指すような言葉が使用できれば伝わりやすくなるケースも少なくありません。
部位の名称やそれぞれの詳細を解説しているページは既にいくつか存在しますが、ここではペパレスのサービス概要と照らし合わせながら解説を行います。
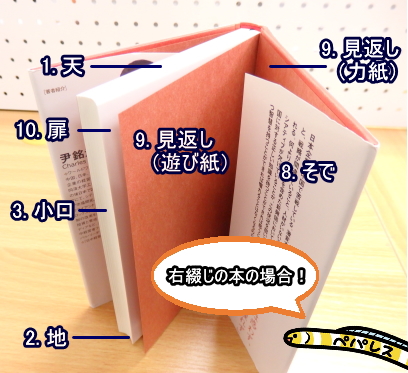


1. 天
本を立てたときに上になる部分(ページの上部)です。
2. 地
本を立てたときに下になる部分(ページの下部)です。
3. 小口
本を開く側です。
背の反対側として使われることが一般的です。
4. 背
本を束ねている部分です。
本を裁断する場合は、この部分を切り落とします。
ペパレスの場合、ハードカバーの本は背を切り落とさず、表紙と中身と分離させる形で裁断しています。
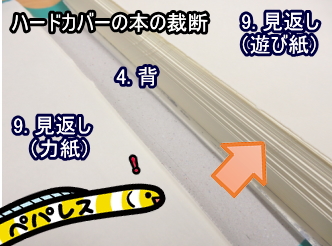
また、再製本サービスでは裁断した本の背の面に専用の糊をつけて本の形に仕上げていきます。

ただし、再製本しても切り落とした背を元通りに接着することはできません。
書籍の返却を希望される方には、切り落とした背も一緒にお返ししています。
5. 表紙
書籍の外側の部分です。
ペパレスでは表表紙が1ページ目、裏表紙が最後尾のページになるようデータを作成しています。
Acrobat上でも自然な本の形になるよう、裏表紙は偶数ページに表示させています。
6. カバー(ジャケット)
表紙の上にかけられている紙です。
元々は表紙の傷みや汚れを防ぐことが目的でしたが、現在では凝ったデザインのものが多くなっています。
ペパレスでは本にカバーがかけられている場合、カバーを表紙としてスキャンし、1ページ目と最後のページに表示させます。
カバーの内側にある表紙は基本的にスキャンしませんが、必要な場合はメールに記載していただければ対応致します。

7. 帯
宣伝のためにカバーに巻いた紙です。「腰巻き」とも言います。
ペパレスでは帯が付属している場合、基本的には取り付けたままスキャンしています。
ただし、そでに書かれている文章が帯で隠れてしまう場合もありますので、必要に応じて外すこともあります。
また、帯が不要な場合はメールに記載していただければ対応致します。

8. そで
カバーや帯を本にかけた際、表紙の内側に折り込む部分です。
9. 見返し
表紙と本の中身をつなぎ合わせる紙です。
表紙の裏側に貼りついている「力紙」と、表紙に接していない「遊び紙」があります。
ペパレスでは、この見返し部分も標準でスキャンしています。
見返しも「表紙」と同様に扱っているため、表紙のスキャンをカラーで指定されている場合はカラーでスキャンします。
10. 扉
見返しの次にあるページです。
書名、著者名、発行所名などが記されます。本文とは異なる紙を使用していることが多いです。
11. スピン
紐しおりです。
本を裁断するとスピンも一緒に裁断されてしまいますので、本を返却する場合でもスピンはこちらで処分します。
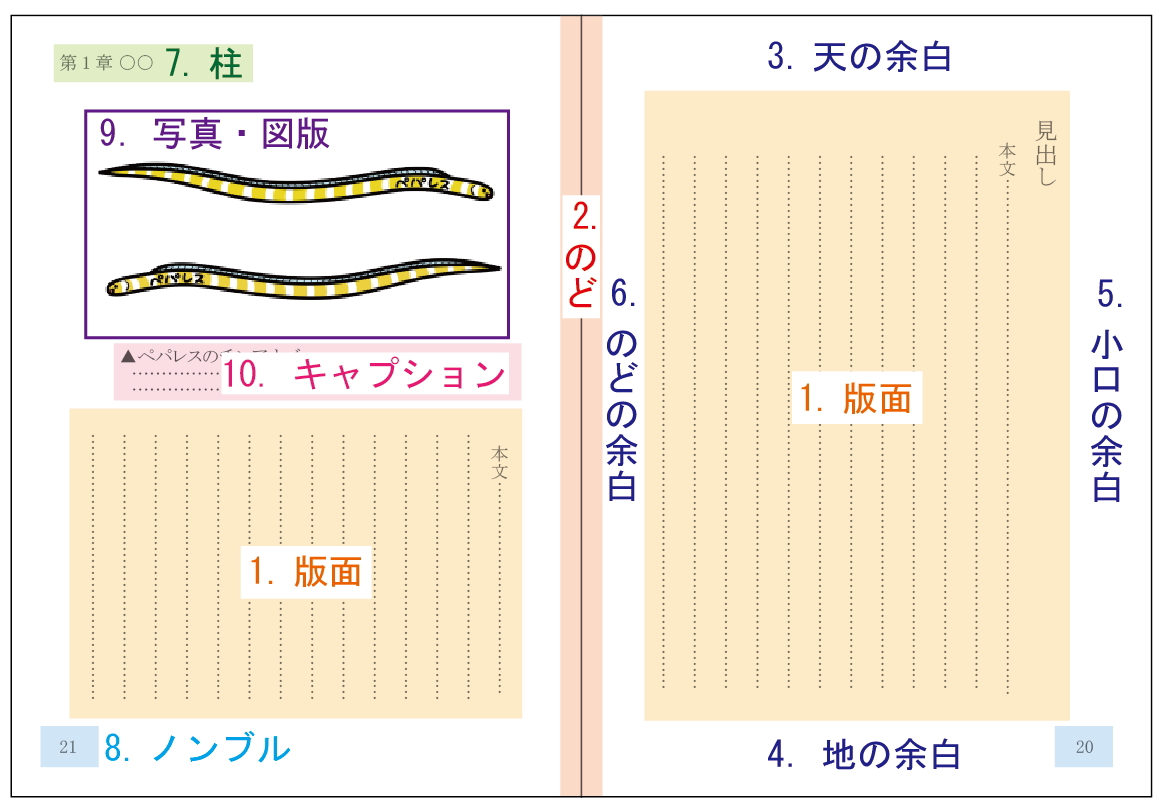
1.版面
本文が印刷されている範囲です。
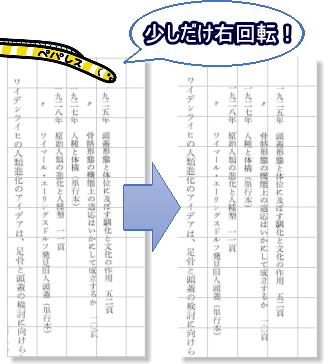
昭和に刊行された古い書籍や洋書は、版面の位置がページによって大きくずれたり傾いたりしていることがあります。
ペパレスでは版面の位置を補正するだけでなく、スキャナーの機能や自社開発のソフトウェアを使用した傾きの補正も行っています。
2. のど
本を綴じている側です。
3.天の余白
4.地の余白
5.小口の余白
6.のどの余白
ペパレスでは原稿をスキャンした後、余白をトリミングしてページサイズを調節します。
版面が狭い本は余白を大幅にカットするなど、それぞれの本に合わせたトリミング作業を行っています。
7.柱
章題や節の見出しなどを表示します。
柱は複数のページに渡って同じ文字列が表示されているので、Acrobatの検索機能を使用すると、それらが必要以上に検索結果に反映されてしまいます。
ペパレスのOCRテキスト化サービスでは、文字抽出の精度に合わせて4段階のレベルのサービスを用意しています。
レベル2以上では文字抽出を行う範囲を手動で設定することができるので、不要な「柱」「ノンブル(ページ番号)」を除いて文字抽出をすることで、検索機能の精度を大幅に上げることができます。
OCRテキスト化サービスの詳細はこちらからご覧ください。
8.ノンブル
ページ番号を表示します。「番号」のフランス語です。
レベル2以上のOCRテキスト化サービスでは、10ページごとにページ番号を文字抽出しています。
必要であれば全ページ番号を抽出、不要であれば全て抽出しないことも可能です。
9.写真・図版
10.キャプション
写真や図版の解説文です。
こちらもレベル2以上のOCRテキスト化サービスでは、文字抽出の対象にするかしないかをお選びいただけます。
本の基本的な部位と名称について解説しましたが、いかがでしたか?
一般的に知られていない名称もあり、そもそもこんな部位に名前があったの?と思われた箇所もあったのではないでしょうか。
ホームページのサービス概要では書ききれない細かい仕様や品質の拘りについても一部記載できたので、サービスの利用を検討される際には、再度目を通していただければ幸いです。
本の部位の名称
本には、あらゆる部位に名称がついています。
表紙や帯など一般的に知られている名称もありますが、本を手に取る機会が多い方の中でも、その詳細を知る人はおそらく限られていることと思います。
ホームページやお問い合わせにてサービスの詳細をお伝えする際、本の各部位を指すような言葉が使用できれば伝わりやすくなるケースも少なくありません。
部位の名称やそれぞれの詳細を解説しているページは既にいくつか存在しますが、ここではペパレスのサービス概要と照らし合わせながら解説を行います。
本の各部名称
1. 天
本を立てたときに上になる部分(ページの上部)です。
2. 地
本を立てたときに下になる部分(ページの下部)です。
3. 小口
本を開く側です。
背の反対側として使われることが一般的です。
4. 背
本を束ねている部分です。
本を裁断する場合は、この部分を切り落とします。
ペパレスの場合、ハードカバーの本は背を切り落とさず、表紙と中身と分離させる形で裁断しています。
また、再製本サービスでは裁断した本の背の面に専用の糊をつけて本の形に仕上げていきます。
ただし、再製本しても切り落とした背を元通りに接着することはできません。
書籍の返却を希望される方には、切り落とした背も一緒にお返ししています。
5. 表紙
書籍の外側の部分です。
ペパレスでは表表紙が1ページ目、裏表紙が最後尾のページになるようデータを作成しています。
Acrobat上でも自然な本の形になるよう、裏表紙は偶数ページに表示させています。
6. カバー(ジャケット)
表紙の上にかけられている紙です。
元々は表紙の傷みや汚れを防ぐことが目的でしたが、現在では凝ったデザインのものが多くなっています。
ペパレスでは本にカバーがかけられている場合、カバーを表紙としてスキャンし、1ページ目と最後のページに表示させます。
カバーの内側にある表紙は基本的にスキャンしませんが、必要な場合はメールに記載していただければ対応致します。
7. 帯
宣伝のためにカバーに巻いた紙です。「腰巻き」とも言います。
ペパレスでは帯が付属している場合、基本的には取り付けたままスキャンしています。
ただし、そでに書かれている文章が帯で隠れてしまう場合もありますので、必要に応じて外すこともあります。
また、帯が不要な場合はメールに記載していただければ対応致します。
8. そで
カバーや帯を本にかけた際、表紙の内側に折り込む部分です。
9. 見返し
表紙と本の中身をつなぎ合わせる紙です。
表紙の裏側に貼りついている「力紙」と、表紙に接していない「遊び紙」があります。
ペパレスでは、この見返し部分も標準でスキャンしています。
見返しも「表紙」と同様に扱っているため、表紙のスキャンをカラーで指定されている場合はカラーでスキャンします。
10. 扉
見返しの次にあるページです。
書名、著者名、発行所名などが記されます。本文とは異なる紙を使用していることが多いです。
11. スピン
紐しおりです。
本を裁断するとスピンも一緒に裁断されてしまいますので、本を返却する場合でもスピンはこちらで処分します。
本の中身の名称
1.版面
本文が印刷されている範囲です。
昭和に刊行された古い書籍や洋書は、版面の位置がページによって大きくずれたり傾いたりしていることがあります。
ペパレスでは版面の位置を補正するだけでなく、スキャナーの機能や自社開発のソフトウェアを使用した傾きの補正も行っています。
2. のど
本を綴じている側です。
3.天の余白
4.地の余白
5.小口の余白
6.のどの余白
ペパレスでは原稿をスキャンした後、余白をトリミングしてページサイズを調節します。
版面が狭い本は余白を大幅にカットするなど、それぞれの本に合わせたトリミング作業を行っています。
7.柱
章題や節の見出しなどを表示します。
柱は複数のページに渡って同じ文字列が表示されているので、Acrobatの検索機能を使用すると、それらが必要以上に検索結果に反映されてしまいます。
ペパレスのOCRテキスト化サービスでは、文字抽出の精度に合わせて4段階のレベルのサービスを用意しています。
レベル2以上では文字抽出を行う範囲を手動で設定することができるので、不要な「柱」「ノンブル(ページ番号)」を除いて文字抽出をすることで、検索機能の精度を大幅に上げることができます。
OCRテキスト化サービスの詳細はこちらからご覧ください。
8.ノンブル
ページ番号を表示します。「番号」のフランス語です。
レベル2以上のOCRテキスト化サービスでは、10ページごとにページ番号を文字抽出しています。
必要であれば全ページ番号を抽出、不要であれば全て抽出しないことも可能です。
9.写真・図版
10.キャプション
写真や図版の解説文です。
こちらもレベル2以上のOCRテキスト化サービスでは、文字抽出の対象にするかしないかをお選びいただけます。
本の基本的な部位と名称について解説しましたが、いかがでしたか?
一般的に知られていない名称もあり、そもそもこんな部位に名前があったの?と思われた箇所もあったのではないでしょうか。
ホームページのサービス概要では書ききれない細かい仕様や品質の拘りについても一部記載できたので、サービスの利用を検討される際には、再度目を通していただければ幸いです。